sprezzatech blog #0009
a disquisition into the sadly slovenly takeup of 10GBASE-T
Fri Jun 8 01:06:06 EDT 2012
Copper GigE descended upon us in 2000 (1999, to be more accurate, as IEEE
802.3ab's 1000BASE-T), and swept all away before it. When we started working on
our Interceptor
IPS product at Reflex in 2000, GigE switches were hundreds of dollars, cards
were close to a hundred each, crossover cables tended to break more problems
than they fixed, and you could count on network admin jerkoffs with more access
than brains hard-coding the duplex and speed settings on switches due to
widespread absence of autonegotiation. That's if you had a switch, which you
 might not, because hubs were quite expensive enough thank you. On the plus
side, IEEE 802.3's 100BASE-TX (2 unidirectional copper UTPs (unshielded twisted
pairs) inside no more than 100m of ANSI/EIA/TIA-568B
8P8C-terminated cable transmitting 4B5B-encoded nibbles using
125MHz clocks, offering 100Mb/s in each of two directions) had pretty much
unified Layers 1 and 2. PCI had unified the expansion bus from a software
perspective (though you had at least 3 parameters in PCI system architecture
(clock, bus width, voltage) and PCI-X had its own 4 clock rates, and PCI was
half-duplex). Onboard FastEthernet was by no means ubiquitous (my first NIC was
a 3Com 905-TX PCI card, installed in 1998 before I headed off to Georgia Tech's
dorms), and onboard 1000BASE-T was unheard of outside rarefied server
motherboards.
might not, because hubs were quite expensive enough thank you. On the plus
side, IEEE 802.3's 100BASE-TX (2 unidirectional copper UTPs (unshielded twisted
pairs) inside no more than 100m of ANSI/EIA/TIA-568B
8P8C-terminated cable transmitting 4B5B-encoded nibbles using
125MHz clocks, offering 100Mb/s in each of two directions) had pretty much
unified Layers 1 and 2. PCI had unified the expansion bus from a software
perspective (though you had at least 3 parameters in PCI system architecture
(clock, bus width, voltage) and PCI-X had its own 4 clock rates, and PCI was
half-duplex). Onboard FastEthernet was by no means ubiquitous (my first NIC was
a 3Com 905-TX PCI card, installed in 1998 before I headed off to Georgia Tech's
dorms), and onboard 1000BASE-T was unheard of outside rarefied server
motherboards.
Annnnnnnd then Apple stuck Marvell 88E8053 GigE onto their PowerMac G4s. And then Intel's 82865/82875 MCH (part of the Springdale and Canterwood chipsets) hung a “Communication Streaming Adapter” off the northbridge, meaning your old Soundblaster's crap PCI performance didn't down-neg most GigE adapters into support call hell. And then a site you might have heard of emerged, which didn't actually need GigE (how often were you mirroring YouTube internally? Online video drove up external bandwidth needs), but sure did make “the damn network slower” and thus added punch and panache to packet providers' purchasing power. And then yea, Moore uttered a barbaric YAWP, taking a great shit upon the land, and doubleplusyea, behold Moore's Load become a bird with three bears for heads, now become a giraffe which keeps all the world in its belly, now killed and consumed at feasts celebrating FDI. Behold many eyes gleaming in Taipei as the wireless revolution primed all of America for home networking upgrades. In 2005, I left Reflex for McAfee, and you'd have been hard-pressed to find FastEthernet beyond the very grimmest of government, medical, and banking networks.
Several Stanford party games involve the myriad 10GigE connectors:
 At many (if not most) sites, only those upgrade paths preserving 1000BASE-T cable
plant investment and GigE coexistence can be seriously considered (Infiniband
sites are cable-compatible with CX4, accounting for most of its 18 or so
known installations). Well, it's been 6 years since IEEE 802.3an-2006 gave us
10GBASE-T, and it's seen
At many (if not most) sites, only those upgrade paths preserving 1000BASE-T cable
plant investment and GigE coexistence can be seriously considered (Infiniband
sites are cable-compatible with CX4, accounting for most of its 18 or so
known installations). Well, it's been 6 years since IEEE 802.3an-2006 gave us
10GBASE-T, and it's seen
The first bitch you'll hear about 10GBASE-T is that of power consumption. It's true that 10GBASE-T is the most inherently power-intensive of the physical layers (though other copper implementations' short ranges keep them from competing outside the server closet), and that early implementations could suck down close to 75W (the maximum power available through a PCIe slot)! Let's whip out Ye Olde Power Equations, broad swords with which we'll hew and hack away at thick kudzus obscuring market viability.
he who has ears, let him hear:
THE POWER EQUATIONS OF LORE
For most CMOS:
P = Pstatic + Pdynamic + Pshort-circuit
where
Pstatic = V * Ileak
Pdynamic = α * C * Vsupp² * F
Pshort-circuit = VDD * ∫t0t1 ISC * τ dτ ∎
But, since we can reduce Pshort-circuit towards 0 by scaling down supply voltage with regards to threshold voltage (VDD ≤ |Vtp| + Vtn → Psc = 0),
P = Pstatic + Pdynamic ∎
Note the prominent role of voltage in both Pstatic and
Pdynamic (in which it is squared). Note furthermore that higher
frequencies require more voltage to be reliably maintained. Note the 3.125GHz clock
at work in 10GBASE-T, 25 times 100BASE-T's 125MHz. Then again, major manufacturers
are now using 65nm and 40nm photolithography processes. The result?
Claiming a 40nm process, Intel's X520,
X540 and AT2 are rated at 13.4W, 19W and 15.5W
respectively. The AT2 is a single port device; no other single port device
comes within 4W. Note that no option comes in under 4.9W. Meanwhile, the
Intel 82574L/IT boasts consumption of only 296mW to perform
FastEthernet, and sips a mere 702mW for 1000BASE-T. Sounds pretty
bad, huh?
I don't think so. First off, those are ratings for active cards. If your card is active, you're doing something with it; unless the increased bandwidth leads to heaving terabits across the network with no purpose, you were presumably going to move all that data. Transfering 100Gb in 10s at even 20W is going to beat doing it in 100s at anything over 2W -- the result is 20J either way (this of course assumes 100% utilization). The need for working PCIe ASPM and ACPI PM (including BIOS support, accurate ACPI firmware, card support, motherboard/PCIe bridge support, and users enabling it throughout the stack) is exacerbated, so that power isn't wasted during periods of low utilization. 10GBASE-T loosens the latency guarantees of 1000BASE-T up to 2–4μs, and that's of course of little importance in the face of multi μs wakeups. Environments demanding lowest latencies will spend a bit of power to do it, but they really ought be looking at specialty fabrics such as Infiniband (~1μs on the best Qlogic and Mellanox HCAs) or optical 10GigE (look at companies like Infinera, Chelsio, and ADVA Optical). If sustained throughput is key, though, and you've got the throughput to drive it, the power argument is in 10GBASE-T's favor, and will swing that way even further as utilization approaches 100%. Issues of space and interconnect design preclude mass teaming of GigE devices.
Still, 20W is nothing to be laughed at; that's a ferromagnetic RAID6 and associated controller infrastructure, or a small GPU. Furthermore, a 48-port 10GBASE-T switch can draw some absolutely serious wattage. On the flip side is increased virtualization density, and the resulting power-saving opportunities.
The issue is, however, generating the kind of sustained loads necessary to make good use of 10GigE. Streaming video? I laugh at you, sir. My server streams unrecoded BluRay to my HTPC over $7 USB wireless cards; Blu-Ray demands a theoretical maximum of 54Mbps, and tends to run closer to 20–30Mbps in practice. To the left you'll find a decrypted RoboCop BluRay image being streamed to XBMC over NFSv4 + IP/TCPv4.
 Nope, stimulating the human sensorium is not a task well-suited to effective
use of 10 Gigabit Ethernet (unless you're providing heterogeneous stimulation
to a decent-sized group of sensoria) (Simulating, on the other hand...read on!). Well, what's more intensive? How about
good ol' bulk file copy? 10GigE is admirably suited for whisking FLACs
and 1080p24 MKVs around one's network, but then again so is regular GigE.
Assuming minimal IP/TCPv4 headers of 40 total bytes (unlikely; TCP timestamps,
among other options, are widespread), and minimal Ethernet overhead of 38
bytes (similarly underestimated due to widespread 802.1q VLAN tagging)
we can hit (1500 - 40) / 1538 ≃ 94.93% protocol efficiency
on Ethernet with a 1500 MTU and 99.13% using 9KB jumbo frames. We've ignored
L4 overhead, and the world is dominated by big pussies, so we'll use the
unjumbified figure. Aforementioned RoboCop rip is 22,213,772,678B according
to du -sb /media/phatty/blurayrips/Robocop, and
(22213772678 * 8) / 949284785 ≃ 188s. Not too shabby! Well, what
about copying a disk image for VM migration? That's sure enough some quality
sittin'-around watchin'-blinkenlights time: (2000 * 1000 * 1000 * 1000 * 8) / 949284785 / 60 / 60 ≃ 4.7h.
Nope, stimulating the human sensorium is not a task well-suited to effective
use of 10 Gigabit Ethernet (unless you're providing heterogeneous stimulation
to a decent-sized group of sensoria) (Simulating, on the other hand...read on!). Well, what's more intensive? How about
good ol' bulk file copy? 10GigE is admirably suited for whisking FLACs
and 1080p24 MKVs around one's network, but then again so is regular GigE.
Assuming minimal IP/TCPv4 headers of 40 total bytes (unlikely; TCP timestamps,
among other options, are widespread), and minimal Ethernet overhead of 38
bytes (similarly underestimated due to widespread 802.1q VLAN tagging)
we can hit (1500 - 40) / 1538 ≃ 94.93% protocol efficiency
on Ethernet with a 1500 MTU and 99.13% using 9KB jumbo frames. We've ignored
L4 overhead, and the world is dominated by big pussies, so we'll use the
unjumbified figure. Aforementioned RoboCop rip is 22,213,772,678B according
to du -sb /media/phatty/blurayrips/Robocop, and
(22213772678 * 8) / 949284785 ≃ 188s. Not too shabby! Well, what
about copying a disk image for VM migration? That's sure enough some quality
sittin'-around watchin'-blinkenlights time: (2000 * 1000 * 1000 * 1000 * 8) / 949284785 / 60 / 60 ≃ 4.7h.
So? A workstation's unlikely to sustain that kind of read speed without SSDs or multiple ferromagnetic devices, on decent controllers, and still more unlikely to approach full 10GigE utilization without very serious investment in IOPs and disk throughput. Given that rotational media is going to max out at a very generous sustained 800Mbps (100MB/s) no matter the generation of SATA implemented. Let's say you've got a truly ballin' 12x2TB-disk RAID6 of these wonderful SATA 3.5" disks supporting sustained 800Mb/s, and backplane to move it all. That's 20TB of data accessible at a peak 9.6Gbps. You move that entire highly unlikely 20TB out in the same 4.68 hours (this is all predicated on at least 4x 5.0GT/s (or 8x 2.5GT/s) PCIe lanes being negotiated to the 10GigE NIC, or you'll be working with 8Gbps or less of PCIe bandwidth). Even if you are in the habit of duplicating 20TB arrays, do you do it every 5 hours? A server sending massive amounts of data to a good number of workstations could of course generate these kinds of loads, but that's no reason to install 10GBASE-T on the recipients, especially while there's such a stark price differential. SSDs simply don't provide enough static data to keep a 10GigE network effectively utilized for significant time. They're too small.
One obvious mass use case remains: distributed computation using systems like OpenMP, especially in the age of heterogeneous, throughput-oriented computing. For problems of arbitrary scale, Gustafson's Law complements Amdahl's somewhat more familiar one (and also Brent's Theorem
 regarding Work/Time models of algorithms): while parallelism's maximum
benefits for a fixed-size problem approach a fixed value, it is possible
for parallelism to provide arbitrary speedup given arbitrary growth in
problem size. The same properties which apply to global memory accesses
vs local shared memory accesses in a CUDA program apply, and apply
to remote node accesses vs local node accesses in a NUMA environment, and
apply to disk vs accesses to memory, apply to network accesses vs disk.
With 10GigE readily outpacing feasible disk access on workstations, this last
relation is inverted—it becomes faster to read data from another
machine's DRAM (especially in the presence of direct cache access) than
from the local disks. In this situation, the aggregate DRAM of all machines
in the cluster becomes a shared, distributed cache for their disks, and a
problem set which can fit entirely within this megacache will enjoy significantly
improved throughput throughout execution.
regarding Work/Time models of algorithms): while parallelism's maximum
benefits for a fixed-size problem approach a fixed value, it is possible
for parallelism to provide arbitrary speedup given arbitrary growth in
problem size. The same properties which apply to global memory accesses
vs local shared memory accesses in a CUDA program apply, and apply
to remote node accesses vs local node accesses in a NUMA environment, and
apply to disk vs accesses to memory, apply to network accesses vs disk.
With 10GigE readily outpacing feasible disk access on workstations, this last
relation is inverted—it becomes faster to read data from another
machine's DRAM (especially in the presence of direct cache access) than
from the local disks. In this situation, the aggregate DRAM of all machines
in the cluster becomes a shared, distributed cache for their disks, and a
problem set which can fit entirely within this megacache will enjoy significantly
improved throughput throughout execution.
In any system design question, we must weigh computational intensity and intensity of memory reference, carefully balancing them. CPU FLOPpage was creeping nicely along; when I took Rich Vuduc's CSE6230, our Nehalems-Es were rated for 8.92 GDFLOPS. I quote a strapping young Nick Black, circa 2009-10:
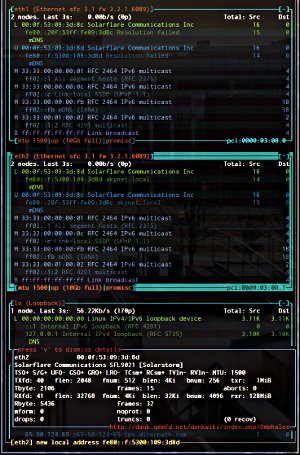
Well hax0rs, once again I've spent the better part of the morning on a blog post. I'll have to cut it off here. Next time, we'll do a careful evaluation of the SolarStorm SFL9021 dual-port 10GBASE-T devices with which SolarFlare claims to be rewriting the latency record books.
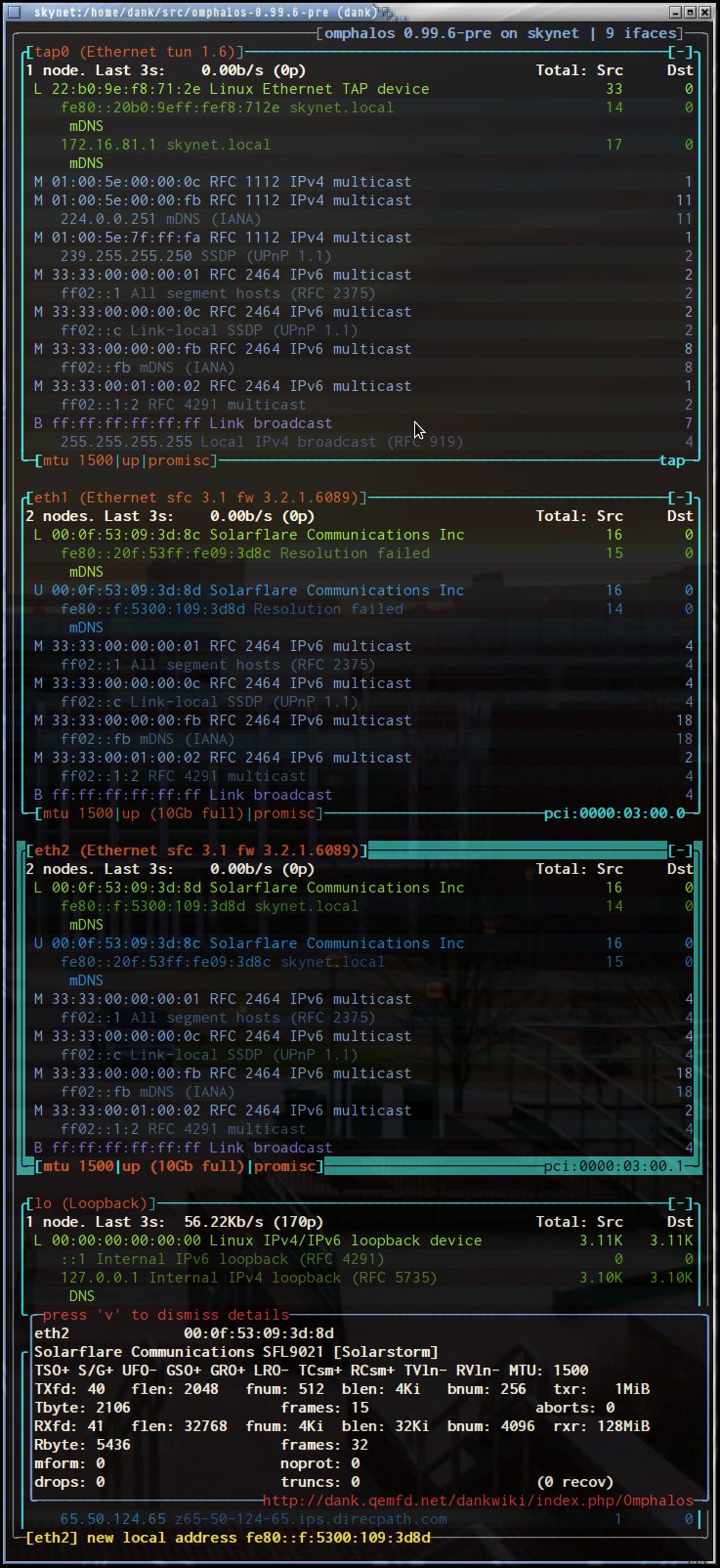
Omphalos loves the smell of 10GigE in the morning. Smells like...victory.
Annnnnnnd then Apple stuck Marvell 88E8053 GigE onto their PowerMac G4s. And then Intel's 82865/82875 MCH (part of the Springdale and Canterwood chipsets) hung a “Communication Streaming Adapter” off the northbridge, meaning your old Soundblaster's crap PCI performance didn't down-neg most GigE adapters into support call hell. And then a site you might have heard of emerged, which didn't actually need GigE (how often were you mirroring YouTube internally? Online video drove up external bandwidth needs), but sure did make “the damn network slower” and thus added punch and panache to packet providers' purchasing power. And then yea, Moore uttered a barbaric YAWP, taking a great shit upon the land, and doubleplusyea, behold Moore's Load become a bird with three bears for heads, now become a giraffe which keeps all the world in its belly, now killed and consumed at feasts celebrating FDI. Behold many eyes gleaming in Taipei as the wireless revolution primed all of America for home networking upgrades. In 2005, I left Reflex for McAfee, and you'd have been hard-pressed to find FastEthernet beyond the very grimmest of government, medical, and banking networks.
Several Stanford party games involve the myriad 10GigE connectors:
The best thing about 10GigE is transferring DVDs more quickly than they can be thrown.
The second best thing is that switches never know which way you'll be coming at 'em.
The second best thing is that switches never know which way you'll be coming at 'em.
IEEE 802.3 dropped two 10GigE PHY layers prior to
802.3an, both of which went exactly nowhere fast due to cabling.
802.3ae-2002 used fiber. 802.3ak-2004's CX4 twin-ax copper crapped out
at 10m.
nothing like GigE's penetration. Without Ye Olde Economies of Scale kicking in,
prices have stayed high, especially for switches.
Even USB (in its 3.0 variant) is claiming 5Gb/s, meaning jerkoff Slashdot-reading
tech ops enjoy more bandwidth to their USB reddit readers than a totally hip
coder/architect like me gets point-to-point among OpenMP nodes, and that
a shirt might be sold on ThinkGeek informing us of this fact, at least until
we belt those goddamn smirks off of their faces (possibly dislodging food particles
from nü-metal beards in the process). How has this unacceptable state of
affairs come to pass? What is required for proper order's restoration?The first bitch you'll hear about 10GBASE-T is that of power consumption. It's true that 10GBASE-T is the most inherently power-intensive of the physical layers (though other copper implementations' short ranges keep them from competing outside the server closet), and that early implementations could suck down close to 75W (the maximum power available through a PCIe slot)! Let's whip out Ye Olde Power Equations, broad swords with which we'll hew and hack away at thick kudzus obscuring market viability.
THE POWER EQUATIONS OF LORE
For most CMOS:
where
Pdynamic = α * C * Vsupp² * F
Pshort-circuit = VDD * ∫t0t1 ISC * τ dτ ∎
But, since we can reduce Pshort-circuit towards 0 by scaling down supply voltage with regards to threshold voltage (VDD ≤ |Vtp| + Vtn → Psc = 0),
I don't think so. First off, those are ratings for active cards. If your card is active, you're doing something with it; unless the increased bandwidth leads to heaving terabits across the network with no purpose, you were presumably going to move all that data. Transfering 100Gb in 10s at even 20W is going to beat doing it in 100s at anything over 2W -- the result is 20J either way (this of course assumes 100% utilization). The need for working PCIe ASPM and ACPI PM (including BIOS support, accurate ACPI firmware, card support, motherboard/PCIe bridge support, and users enabling it throughout the stack) is exacerbated, so that power isn't wasted during periods of low utilization. 10GBASE-T loosens the latency guarantees of 1000BASE-T up to 2–4μs, and that's of course of little importance in the face of multi μs wakeups. Environments demanding lowest latencies will spend a bit of power to do it, but they really ought be looking at specialty fabrics such as Infiniband (~1μs on the best Qlogic and Mellanox HCAs) or optical 10GigE (look at companies like Infinera, Chelsio, and ADVA Optical). If sustained throughput is key, though, and you've got the throughput to drive it, the power argument is in 10GBASE-T's favor, and will swing that way even further as utilization approaches 100%. Issues of space and interconnect design preclude mass teaming of GigE devices.
Still, 20W is nothing to be laughed at; that's a ferromagnetic RAID6 and associated controller infrastructure, or a small GPU. Furthermore, a 48-port 10GBASE-T switch can draw some absolutely serious wattage. On the flip side is increased virtualization density, and the resulting power-saving opportunities.
The issue is, however, generating the kind of sustained loads necessary to make good use of 10GigE. Streaming video? I laugh at you, sir. My server streams unrecoded BluRay to my HTPC over $7 USB wireless cards; Blu-Ray demands a theoretical maximum of 54Mbps, and tends to run closer to 20–30Mbps in practice. To the left you'll find a decrypted RoboCop BluRay image being streamed to XBMC over NFSv4 + IP/TCPv4.
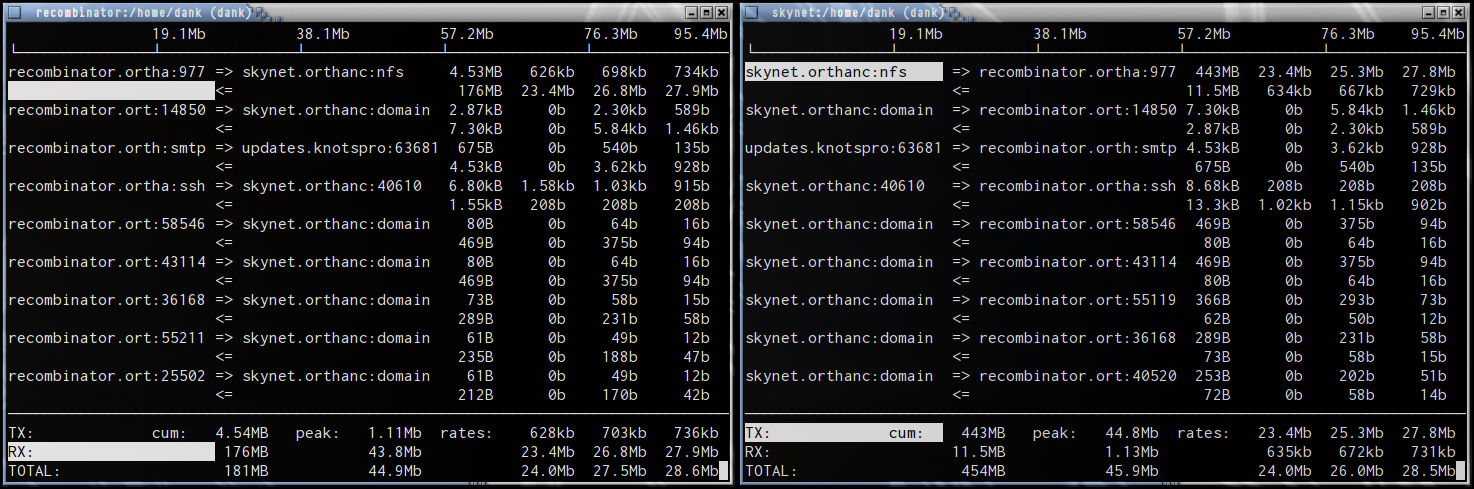
Absolute garbage Rosewill-branded Realtek controllers. The best thing about
them is that they don't, like, actively drive themselves into your eye.
So? A workstation's unlikely to sustain that kind of read speed without SSDs or multiple ferromagnetic devices, on decent controllers, and still more unlikely to approach full 10GigE utilization without very serious investment in IOPs and disk throughput. Given that rotational media is going to max out at a very generous sustained 800Mbps (100MB/s) no matter the generation of SATA implemented. Let's say you've got a truly ballin' 12x2TB-disk RAID6 of these wonderful SATA 3.5" disks supporting sustained 800Mb/s, and backplane to move it all. That's 20TB of data accessible at a peak 9.6Gbps. You move that entire highly unlikely 20TB out in the same 4.68 hours (this is all predicated on at least 4x 5.0GT/s (or 8x 2.5GT/s) PCIe lanes being negotiated to the 10GigE NIC, or you'll be working with 8Gbps or less of PCIe bandwidth). Even if you are in the habit of duplicating 20TB arrays, do you do it every 5 hours? A server sending massive amounts of data to a good number of workstations could of course generate these kinds of loads, but that's no reason to install 10GBASE-T on the recipients, especially while there's such a stark price differential. SSDs simply don't provide enough static data to keep a 10GigE network effectively utilized for significant time. They're too small.
One obvious mass use case remains: distributed computation using systems like OpenMP, especially in the age of heterogeneous, throughput-oriented computing. For problems of arbitrary scale, Gustafson's Law complements Amdahl's somewhat more familiar one (and also Brent's Theorem

What rough beast, its hour come round at last, slouches towards Atlanta IX to be born?
In any system design question, we must weigh computational intensity and intensity of memory reference, carefully balancing them. CPU FLOPpage was creeping nicely along; when I took Rich Vuduc's CSE6230, our Nehalems-Es were rated for 8.92 GDFLOPS. I quote a strapping young Nick Black, circa 2009-10:
“Unfortunately, Intel has not documented the write ports and execution units each instruction can use on Nehelam, nor released details of the execution core save some general schematics. Likewise, Agner Fog's Instruction Timing Tables have yet to be updated with Nehelem data. We assumed the 2 "SSE Logic" units shown in these schemata could handle any SSE logic or arithmetic instruction; experience with our SSE kernel, however, suggests an "SSE_Add/SSE_Mul" split, of which the dot product instructions can only run on SSE_Mul.Well, with 8.92 measley GDFLOPS (3 * 72 = 216Gbps) when acting on registers, you're not going to be effectively pulling down 10Gbps from the truly last cache. Start throwing in multi-TSFLOP 16x PCIe 3.0 cards, though, and it's a very real possibility. Molecular dynamics, ahoy!
Peak double precision floating point ops per second is thus 8.92: a 2.23GHz clock drives two floating point arithmetic units capable of SIMD operation on 2 64-bit IEEE 754 values. Due to the divergent capabilities of the two units, this is more accurately 2.23GFlops of 2-unit additions and 2.23GFlops of 2-unit multiplications. Naive matrix multiply pairs additions off with multiplications, so a combined peak of 8.92GFlops indeed ought be attainable.”
Well hax0rs, once again I've spent the better part of the morning on a blog post. I'll have to cut it off here. Next time, we'll do a careful evaluation of the SolarStorm SFL9021 dual-port 10GBASE-T devices with which SolarFlare claims to be rewriting the latency record books.